On 2nd September 2025 the matrix.org homeserver suffered a ~24h outage.
During routine maintenance to increase disk capacity, the primary database failed, and we fell back to the secondary. In attempting to restore the original primary, we lost the secondary-turned-primary rendering matrix.org unavailable.
To recover, it was necessary to restore from S3 storage, however the restore process was lengthy due to the size of the dataset (51TB).
The matrix.org homeserver was unavailable from 2025-09-02 17:45 UTC and full service resumed at 2025-09-03 18:00 UTC. No data was lost as a result of the incident.
🔗What happened
The matrix.org homeserver is made of a main Synapse instance with hundreds of workers, backed by a single logical Postgres cluster made up of two machines. The primary database is replicated to a secondary, read-only instance via streaming replication.
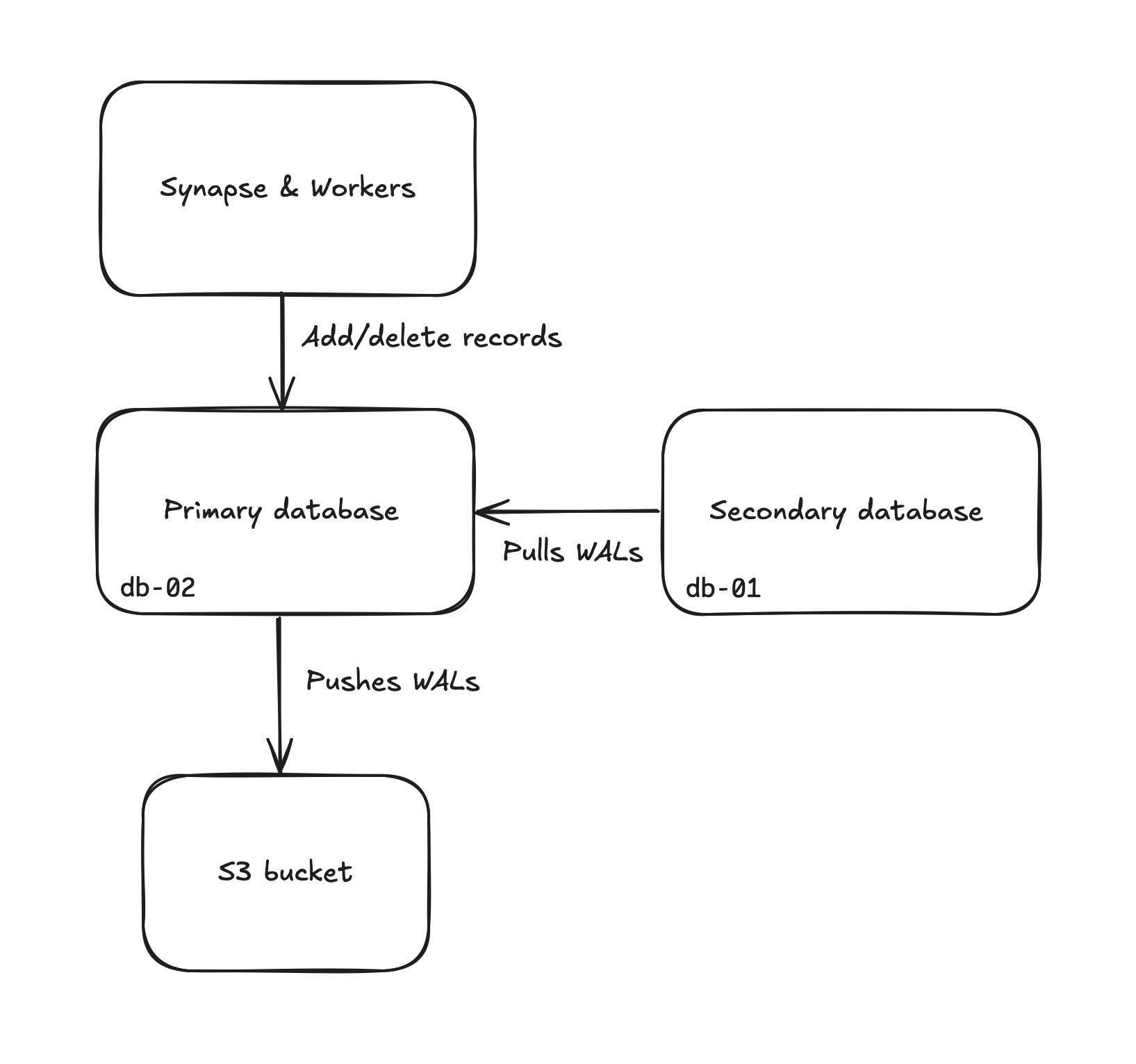
A schema showing Synapse connected to a primary database. It also shows a secondary database pulling WALs from the primary. Finally the primary database also pushes WALs to a S3 bucket
Confusingly, at the time of the incident, the primary database server is called db-02, and the secondary database server is called db-01. The deployment runs on bare metal servers at Mythic Beasts and the Postgres database servers both use their own logical RAID 10 array with mdraid.
Our primary database is backed up to an S3 bucket in AWS. At the time of the incident, we performed a full database backup weekly, incremental database backups daily, and we archived WALs continuously to a separate S3 bucket. If you are not familiar with WALs, you can see them as the primary database recording what it does when inserting or removing records into its tables.
Since WALs are exact records of what happened, they can be useful for two things
- Archive/backups. WALs can be seen as “small incremental backups” to aid point-in-time recovery and/or bridge the gap between full backups. This is why we keep them in the S3 bucket in addition to the weekly and daily backups.
- Replication. The secondary database will fetch those WALs from the primary database and also replay them on itself, to have the exact same records as the primary database.
The primary database will produce WALs as it adds or removes records, and keep them until they have been both archived to a S3 bucket and been fetched by the secondary database.
We monitor the database size and growth, and when the database reached roughly 51TB (90% of disk capacity) we set about adding more disks in the array.
🔗Timeline
At 11:03 UTC on Sept 2nd 2025, Mythic Beasts’ teams added 2 NVMe drives to both db-02 and db-01, respectively the primary and secondary database servers.
At 11:17 UTC, one existing drive disappeared from the RAID array of db-02, our primary database server. Our monitoring fired, and Mythic Beasts confirmed the issue. Because we’re using RAID 10, the setup was still functional but running in degraded mode. There was no data loss, but the RAID array could potentially not survive another drive failure, and performance could be degraded.
We had to restore the RAID array of db-02, our primary database server, to a non-degraded state. That meant failing over to our secondary database on db-01 and doing maintenance on db-02, a decision we took at 12:57 UTC.
At 13:27 UTC the fail-over to the database on db-01 was complete, and db-01 was now the primary. Synapse happily started writing to it. At this point there has been minimal disruption. But the new primary didn’t archive WALs to S3 due to an issue in the archiving script. Because of this and because the new secondary was offline, WALs could not be discarded from db-01 yet.
At 13:30 UTC, we restarted the postgres instance on db-02 in replica mode, effectively turning our former primary database into a secondary. The new secondary needed to catch up with what had been happening on the new primary running on db-01 by consuming its WALs.
At 13:53 UTC, after the new secondary on db-02 caught up with the new primary on db-01, we decided to restart the db-02 server, in the hope of restoring its RAID 10 array to a fully functional state.
At 14:01 UTC, the db-02 server rebooted in recovery mode, because its RAID array could not be assembled as an additional drive was now missing. Recovery mode means no network, no ssh, no postgres instance was running. At this point, our secondary database was offline, and our new primary still didn’t archive WALs to S3. WALs kept accumulating on db-01.
At 15:44 UTC, we reached the conclusion that
- The RAID array on our
db-02server was not recoverable as the RAID headers were missing on both drives that were missing from the RAID array. - We needed to recreate a fresh RAID array.
- We would need to restore the database on
db-02, ideally by making it a replica of the new primary running ondb-01.
At 16:11 UTC, the db-02 server went back online with a fresh RAID 10 array, and by 16:50 UTC we unblocked the WALs archival from the primary on db-01 to S3. WALs could start being discarded on the primary on db-01; it was time to restore the secondary on db-02.
At 17:20 UTC, we upgraded the Postgres on the brand new and empty secondary on db-02 to the latest patch version. That meant not having to do another set of failovers to upgrade the databases after getting back to a healthy state. At this point, we still had a fully functional primary database.
At 17:25 UTC we attempted to start restoring the data on db-02.
First we ran a command on the machine to list all of the backups and identify the correct backup ID:
sudo /opt/wal-g/wal-g \
--walg-s3-prefix=s3://<backup-bucket> \
--aws-shared-credentials-file=/home/postgres/.aws/credentials \
--aws-region=eu-west-2 backup-list
We were able to identify the most recent backup and target it with a restore command that we have documented as part of our restore procedures:
sudo time /opt/wal-g/wal-g \
--walg-s3-prefix=s3://<backup-bucket> \
--aws-shared-credentials-file=/home/postgres/.aws/credentials \
--aws-region=eu-west-2 \
--walg-download-concurrency=32 \
backup-fetch /mnt/data/postgresql-14/ <backup_id> \
2>&1 | tee restore.log
This command was entered while the current directory was the Postgres database directory, which caused the tee command to fail and abort the restore process, which had enough time to create some directories in the data path but nothing else. We switched to the home path and re-ran the command, which successfully wrote to the log file, but failed due to the data directory being non-empty after the previous aborted restore.
The necessary course of action at this point was to clear the remains of the failed restore attempt from the data directory and start again. Since db-02 had already been cleared and needed to be restored, this didn’t register as a particularly high risk manoeuvre.
Unfortunately, in attempting to do so, we erroneously deleted the data directory of the primary on db-01.
After realising our mistake, we decided to keep our Postgres up on db-01 in case deleted files were still open in Postgres processes, with the hopes that the open file handles would forestall the actual deletion of the data on disk.
With both db-01 and db-02 out of action we had no other option but to restore at least one database from offsite backup. Since db-02 was in a pristine state, with an expanded RAID array, we decided to restore the database on this server.
As detailed earlier, our backup strategy at the time was: full database backups weekly, incremental database backups daily, and WALs archival continuously. To perform a complete backup without any data loss on db-02, we needed to
- Restore the latest weekly full database backup from S3.
- Restore all the daily incremental backups from S3 since the last daily backup.
- Replay the WALs since the last daily incremental backup.
So at 17:30 UTC, we started restoring the database on db-02 by using wal-g - a well known tool that pulls the backups from S3 to restore databases. That was going to be costly and slow, but we didn’t have a choice and that’s what backups are for.
In the meantime, the backend team was paged to manage the impact to Synapse, an incident was opened, and an emergency was declared. Our primary database on db-01 was partially wiped and throwing errors, but not corrupt enough to crash Synapse. We decided to shut down both Synapse and the primary database to avoid unknown database states. At this point, the matrix.org homeserver was down.
At 18:06 UTC we decided to re-mount the data partition of db-01 as read-only. We were now in emergency mode, and wanted to ensure we couldn’t damage the database further, in case we could salvage it later.
At 18:40 UTC, after taking the time to consider our options, we realised the following
- extundelete and ext4magic were both unmaintained for a decade, and are unable to work on an unmounted filesystem. ext4magic even explicitly documents it “can no longer successfully process current ext4 file systems”
- We also tried R-Linux, but weren’t confident in the integrity of the recovered files - especially with our recent experiences with slow-burning postgres corruption.
- So we decided against trying to recover the lost data by carving or undeletion, in favour of a guaranteed reliable restore from offsite backup.
At 20:30 UTC, db-02 was still restoring from the S3 backup. After restoring the database on db-02 from its full and incremental backups, we would need to replay the WALs produced by db-01 to fill the gap between the last backup taken from db-02 and the moment we lost db-01.
When we promoted db-01 as the primary, the script that archives WALs to S3 started erroring out. As a result, there were WALs on db-01 that were not in S3. We were going to need those to bring db-02 up to date with the point of the outage. We started copying these WALs from db-01 to db-02 to have them ready to replay once the restore from S3 backup would complete. Restoring 51 TB from S3 takes time so we didn’t have much more to do than wait for the restore to complete.
At 07:21 UTC the next morning, the data extraction from the full weekly backup was complete. However as soon as wal-g attempted to start restoring the next daily increment backup it immediately errored out due to an issue with wal-g that had already received a fix. Now, we regularly run backup recovery tests during which we spin up a short lived EC2 instance, called our Disaster Recovery Server, perform a full database restore on it and run a few tests before tearing it down. During one of those recovery tests, we had already run into the wal-g problem and fixed it in the backup recovery test ansible playbook… but unfortunately this got missed on the actual database servers.
This meant that our production version of wal-g was outdated and hadn’t received this fix. At this point, we had pulled all the full base backup data from S3, but wal-g had failed to restore any incremental backups on top of it because of this bug. We needed to update wal-g to the latest release of the same major version to benefit from the fix. After doing so, we tried to relaunch the restore, and it failed because the data directory already contained a partial restore.
So, we decided to patch wal-g to recover from a partial failed restore, and after fighting with the dependencies we figured out how to make it accept a non-empty data directory that contained a pristine full base backup, so we didn’t have to pull everything from S3 again. We patched it, built it, and used it against db-02 at 09:23 UTC.
At 09:35 UTC the first incremental backup was restored, then the second at 09:44 UTC, the third at 09:54 UTC, and the final backup was restored at 10:03 UTC.
At 10:45 UTC we attempted to start the new instance in standby mode to check its consistency. But the standby mode of Postgres is meant to be for replicas, and replicas need either a primary to grab WALs from, or a remote_command set to fetch WALs. Since the new Postgres on db-02 couldn’t reach any primary and it didn’t have any restore_command set, it refused to start in standby mode.
So we configured a restore_command with a wrapper script that could fetch WALs from both S3 (our “continuous backups”) or from the filesystem (db WALs carried over from db-01) and started Postgres in standby mode successfully. It started catching up on WALs from S3 at 11:00 UTC.
Frustratingly, the playback rate was slower than expected - to replay the ~18 hours of WALs ended up taking 5.5 hours (we had been hoping it would take around 10 minutes for every 1 hour of WALs). It took until 16:27 UTC to replay all the WALs. And at this point we could log into the Postgres database on db-02.
At long last, we had a working database instance, with no data loss. We promoted it to a primary database at 16:45 UTC, and started a Synapse test worker at 16:51 UTC. We could see new WALs start to appear in S3, which meant WAL shipping worked. It was time to restart Synapse and bring matrix.org back online. We started Synapse at 16:54 UTC, and after various thundering-herd overloads as everyone reconnected, all the workers were online and stable by 18:00 UTC.
At this point, the server was back online, matrix.org was catching up with everything that had happened on the rest of the federation while it was offline, albeit with a single database node (although WALs were being archived to S3 for safety).
At this point, if our database had caught fire we could have been able to restore it without losing data, but at the cost of bringing matrix.org offline again. We had just been through it, we didn’t want to do it again. We needed our secondary back.
But we also needed the team to get some rest. Given how slow it was to replay WALs, we reconfigured our backups to happen against the primary database rather than against the (missing) replica. We let the European team go to bed, while our American SRE kept tabs on everything. At 03:26 UTC a new incremental backup completed.
At 09:21 UTC we added the two NVMe disks to the RAID array and to the LVM volumes group of db-01. We rebooted to ensure the disks were properly detected and mounted - but the server didn’t come back. We opened the lights-out console Mythic Beasts provides us, and saw that the RAID array was not in the functional state. We had rebooted db-01 at a critical moment of the array reshaping.
After fixing up the array to bring it in a bootable state, db-01 finally restarted, and we copied over the basebackup from db-02 and set it to replicating.
🔗Lessons learned
🔗We have a massive database
A lot of the pain we experienced during this outage came from how massive our database is.
- Now that we have extra storage, it’s the right time to run
pg_repackand reclaim free space. - We have already increased the frequency of incremental backups, since they’re much faster to restore than it is to replay WALs.
- We also know Synapse could do much better in terms of data storage and there are plans to drastically reduce storage requirements in future, also see Matthew’s “how hard could it be” hack from the week before the incident: https://youtu.be/D5zAgVYBuGk?t=1852.
🔗Our safeguards can be improved
Running a destructive command on the incorrect server was a key moment in the incident. While it can be attributed to human error, it is incorrect to focus on the individual, and instead consider how to improve the tooling and processes surrounding them to minimise the chances of a repeat in the future.
On making the sensitive changes, the on-call group effectively paired as a trio, however, in the heat of the moment, this was insufficient to catch the error.
We realised that the database servers names were a source of confusion. db-01 reads like “Primary DB” and db-02 reads like “Secondary DB”. Not only is this false in our case, a primary database server can become a secondary database server, and the other way around. Names with intrinsic meanings are a source of confusion.
We’re considering changing the background colour of the terminal dynamically depending on the role the database is playing in the cluster. An idea we floated is to monitor the presence of the standby.signal file in the database data directory to know whether it is a primary or a secondary database, and update the terminal’s background colour accordingly. This is not a silver bullet since the background colour would only change after a command has been sent, but that would already be an improvement.
We also discussed wrapper scripts around sensitive commands (such as an alias for rm) or automating some operations, such as starting a base backup from primary to secondary as a means to minimise risk.
We could restore the service after 24h offline, without any data loss despite losing both our primary and secondary databases. This accounts for a great Recovery Point Objective and is testament to our PITR processes that we test regularly. We should take pride in the recovery, but we need to work on a shorter Recovery Time Objective, we’re currently talking to service providers to get free infrastructure that would make it easier and faster to recover.
🔗We can have better tools
We upgraded wal-g on all servers, not just the Disaster Recovery Server, and have done a round of Disaster Recovery testing with it. We didn’t explore yet how we can ensure the Disaster Recovery Server and the production servers can stay aligned.
At the next hardware refresh, we will explore using ZFS so we can make local snapshots and recover much more quickly from not so happy accidents such as accidentally wiping the wrong database.
🔗We have a great community and providers
We received a lot of support on social media where we communicated actively around the incident. This was welcomed positively by the broad community, despite our status page not receiving the attention it deserved. We’re adding steps to our incident response playbook to update status.matrix.org as the canonical source of truth during an incident, and liaise with the advocacy team to keep social media updated as well.
The SRE team would like to thank our hosting provider Mythic Beasts. They reached out quickly and proactively when adding new disks, reporting the errors they were seeing. They have been much more than just a pair of remote hands. They also reached out with an offer of support during the incident.
Finally, we’d like to sincerely apologise again to everyone impacted by the outage. We hope you found the post-mortem informative and you’d like to talk about it more, several of us will be at the Matrix Conference 2025 in Strasbourg. In addition to a flurry of great talks, there will be workshops about how to set up a Matrix homeserver and tune the clients to your liking!
The Foundation needs you
The Matrix.org Foundation is a non-profit and only relies on donations to operate. Its core mission is to maintain the Matrix Specification, but it does much more than that.
It maintains the matrix.org homeserver and hosts several bridges for free. It fights for our collective rights to digital privacy and dignity.
Support us